| 1 | Join order[1]: STUDENT[S]#0 TAKES[T]#1 |
| 2 | |
| 3 | *************** |
| 4 | Now joining: TAKES[T]#1 |
| 5 | *************** |
| 6 | NL Join |
| 7 | Outer table: Card: 13.000000 Cost: 5.000998 Resp: 5.000998 Degree: 1 Bytes: |
| 8 | Access path analysis for TAKES |
| 9 | Scan IO Cost (Disk) = 3.076923 |
| 10 | Scan CPU Cost (Disk) = 41107.200000 |
| 11 | Total Scan IO Cost = 3.076923 (scan (Disk)) |
| 12 | + 0.000000 (io filter eval) (= 0.000000 (per row) * 22.000000 (#rows)) |
| 13 | 3.076923 |
| 14 | Total Scan CPU Cost = 41107.200000 (scan (Disk)) |
| 15 | + 1100.000000 (cpu filter eval) (= 50.000000 (per row) * 22.000000 (#rows)) |
| 16 | 42207.2 |
| 17 | Inner table: TAKES Alias: T |
| 18 | Access Path: TableScan |
| 19 | NL Join: Cost: 45.015282 Resp: 45.015282 Degree: 1 |
| 20 | Cost_io: 45.000000 Cost_cpu: 587031 |
| 21 | Resp_io: 45.000000 Resp_cpu: 587031 |
| 22 | ****** Costing Index SYS_C0014106 |
| 23 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN |
| 24 | |
| 25 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER |
| 26 | |
| 27 | Access Path: index (RangeScan) |
| 28 | Index: SYS_C0014106 |
| 29 | resc_io: 2.000000 resc_cpu: 15143 |
| 30 | ix_sel: 0.083333 ix_sel_with_filters: 0.083333 |
| 31 | NL Join : Cost: 30.005924 Resp: 30.005924 Degree: 1 |
| 32 | Cost_io: 30.000000 Cost_cpu: 227573 |
| 33 | Resp_io: 30.000000 Resp_cpu: 227573 |
| 34 | |
| 35 | Best NL cost: 30.005924 |
| 36 | resc: 30.005924 resc_io: 30.000000 resc_cpu: 227573 |
| 37 | resp: 30.005924 resp_io: 30.000000 resc_cpu: 227573 |
| 38 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = JOIN |
| 39 | Join Card: 22.000000 = outer (13.000000) * inner (22.000000) * sel (0.076923) |
| 40 | Join Card – Rounded: 22 Computed: 22.000000 |
| 41 | Outer table: STUDENT Alias: S |
| 42 | resc: 5.000998 card 13.000000 bytes: deg: 1 resp: 5.000998 |
| 43 | Inner table: TAKES Alias: T |
| 44 | resc: 5.001070 card: 22.000000 bytes: deg: 1 resp: 5.001070 |
| 45 | using dmeth: 2 #groups: 1 |
| 46 | SORT ressource Sort statistics |
| 47 | Sort width: 118 Area size: 131072 Max Area size: 20971520 |
| 48 | Degree: 1 |
| 49 | Blocks to Sort: 1 Row size: 38 Total Rows: 13 |
| 50 | Initial runs: 1 Merge passes: 0 IO Cost / pass: 0 |
| 51 | Total IO sort cost: 0.000000 Total CPU sort cost: 38415391 |
| 52 | Total Temp space used: 0 |
| 53 | SORT resource Sort statistics |
| 54 | Sort width: 118 Area size: 131072 Max Area size: 20971520 |
| 55 | Degree: 1 |
| 56 | Blocks to Sort: 1 Row size: 40 Total Rows: 22 |
| 57 | Initial runs: 1 Merge passes: 0 IO Cost / pass: 0 |
| 58 | Total IO sort cost: 0.000000 Total CPU sort cost: 38417643 |
| 59 | Total Temp space used: 0 |
| 60 | SM join: Resc: 12.002240 Resp: 12.002240 [multiMatchCost=0.000000] |
| 61 | SM Join |
| 62 | SM cost: 12.002240 |
| 63 | resc: 12.002240 resc_io: 10.000000 resc_cpu: 76912478 |
| 64 | resp: 12.002240 resp_io: 10.000000 resp_cpu: 76912478 |
| 65 | SM Join (with index on outer) |
| 66 | ****** Costing Index SYS_C0015206 |
| 67 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER |
| 68 | Access Path: index (FullScan) |
| 69 | Index: SYS_C0015206 |
| 70 | resc_io: 2.000000 resc_cpu: 19573 |
| 71 | ix_sel: 1.000000 ix_sel_with_filters: 1.000000 |
| 72 | Cost: 2.000510 Resp: 2.000510 Degree: 1 |
| 73 | Outer table: STUDENT Alias: S |
| 74 | resc: 2.000510 card 13.000000 bytes: deg: 1 resp: 2.000510 |
| 75 | Inner table: TAKES Alias: T |
| 76 | resc: 5.001070 card: 22.000000 bytes: deg: 1 resp: 5.001070 |
| 77 | using dmeth: 2 #groups: 1 |
| 78 | SORT ressource Sort statistics |
| 79 | Sort width: 118 Area size: 131072 Max Area size: 20971520 |
| 80 | Degree: 1 |
| 81 | Blocks to Sort: 1 Row size: 40 Total Rows: 22 |
| 82 | Initial runs: 1 Merge passes: 0 IO Cost / pass: 0 |
| 83 | Total IO sort cost: 0.000000 Total CPU sort cost: 38417643 |
| 84 | Total Temp space used: 0 |
| 85 | SM join: Resc: 8.001695 Resp: 8.001695 [multiMatchCost=0.000000] |
| 86 | Outer table: STUDENT Alias: S |
| 87 | resc: 5.000998 card 13.000000 bytes: deg: 1 resp: 5.000998 |
| 88 | Inner table: TAKES Alias: T |
| 89 | resc: 5.001070 card: 22.000000 bytes: deg: 1 resp: 5.001070 |
| 90 | using dmeth: 2 #groups: 1 |
| 91 | Cost per ptn: 0.015728 #ptns: 1 |
| 92 | hash_area: 124 (max=5120) buildfrag: 1 probefrag: 1 ppasses: 1 |
| 93 | Hash join: Resc: 10.017796 Resp: 10.017796 [multiMatchCost=0.000000] |
| 94 | HA Join |
| 95 | HA cost: 10.017796 |
| 96 | resc: 10.017796 resc_io: 10.000000 resc_cpu: 683594 |
| 97 | resp: 10.017796 resp_io: 10.000000 resp_cpu: 683594 |
| 98 | Best:: JoinMethod: SortMerge |
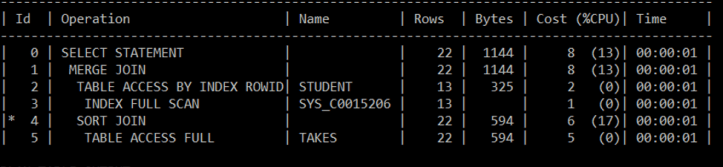
| 99 | Cost: 8.001695 Degree: 1 Resp: 8.001695 Card: 22.000000 Bytes: |
| 100 | *********************** |
| 101 | Best so far: Table#: 0 cost: 2.000510 card: 13.000000 bytes: 325.000000 |
| 102 | Table#: 1 cost: 8.001695 card: 22.000000 bytes: 1144.000000 |
| 103 | *********************** |
| 104 | Join order[2]: TAKES[T]#1 STUDENT[S]#0 |
| 105 | |
| 106 | *************** |
| 107 | Now joining: STUDENT[S]#0 |
| 108 | *************** |
| 109 | NL Join |
| 110 | Outer table: Card: 22.000000 Cost: 5.001070 Resp: 5.001070 Degree: 1 Bytes: |
| 111 | Access path analysis for STUDENT |
| 112 | Scan IO Cost (Disk) = 3.000000 |
| 113 | Scan CPU Cost (Disk) = 38337.200000 |
| 114 | Total Scan IO Cost = 3.000000 (scan (Disk)) |
| 115 | + 0.000000 (io filter eval) (= 0.000000 (per row) * 13.000000 (#rows)) |
| 116 | 3 |
| 117 | Total Scan CPU Cost = 38337.200000 (scan (Disk)) |
| 118 | + 650.000000 (cpu filter eval) (= 50.000000 (per row) * 13.000000 (#rows)) |
| 119 | 38987.2 |
| 120 | Inner table: STUDENT Alias: S |
| 121 | Access Path: TableScan |
| 122 | NL Join: Cost: 71.023399 Resp: 71.023399 Degree: 1 |
| 123 | Cost_io: 71.000000 Cost_cpu: 898826 |
| 124 | Resp_io: 71.000000 Resp_cpu: 898826 |
| 125 | ****** Costing Index SYS_C0015206 |
| 126 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN |
| 127 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER |
| 128 | Access Path: index (UniqueScan) |
| 129 | Index: SYS_C0015206 |
| 130 | resc_io: 1.000000 resc_cpu: 8381 |
| 131 | ix_sel: 0.076923 ix_sel_with_filters: 0.076923 |
| 132 | NL Join : Cost: 27.005870 Resp: 27.005870 Degree: 1 |
| 133 | Cost_io: 27.000000 Cost_cpu: 225499 |
| 134 | Resp_io: 27.000000 Resp_cpu: 225499 |
| 135 | ****** Costing Index SYS_C0015206 |
| 136 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN |
| 137 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER |
| 138 | Access Path: index (AllEqUnique) |
| 139 | Index: SYS_C0015206 |
| 140 | resc_io: 1.000000 resc_cpu: 8381 |
| 141 | ix_sel: 0.076923 ix_sel_with_filters: 0.076923 |
| 142 | NL Join : Cost: 27.005870 Resp: 27.005870 Degree: 1 |
| 143 | Cost_io: 27.000000 Cost_cpu: 225499 |
| 144 | Resp_io: 27.000000 Resp_cpu: 225499 |
| 145 | |
| 146 | Best NL cost: 27.005870 |
| 147 | resc: 27.005870 resc_io: 27.000000 resc_cpu: 225499 |
| 148 | resp: 27.005870 resp_io: 27.000000 resc_cpu: 225499 |
| 149 | SPD: Return code in qosdDSDirSetup: NOCTX, estType = JOIN |
| 150 | Join Card: 22.000000 = outer (22.000000) * inner (13.000000) * sel (0.076923) |
| 151 | Join Card – Rounded: 22 Computed: 22.000000 |
| 152 | Outer table: TAKES Alias: T |
| 153 | resc: 5.001070 card 22.000000 bytes: deg: 1 resp: 5.001070 |
| 154 | Inner table: STUDENT Alias: S |
| 155 | resc: 5.000998 card: 13.000000 bytes: deg: 1 resp: 5.000998 |
| 156 | using dmeth: 2 #groups: 1 |
| 157 | SORT ressource Sort statistics |
| 158 | Sort width: 118 Area size: 131072 Max Area size: 20971520 |
| 159 | Degree: 1 |
| 160 | Blocks to Sort: 1 Row size: 40 Total Rows: 22 |
| 161 | Initial runs: 1 Merge passes: 0 IO Cost / pass: 0 |
| 162 | Total IO sort cost: 0.000000 Total CPU sort cost: 38417643 |
| 163 | Total Temp space used: 0 |
| 164 | SORT ressource Sort statistics |
| 165 | Sort width: 118 Area size: 131072 Max Area size: 20971520 |
| 166 | Degree: 1 |
| 167 | Blocks to Sort: 1 Row size: 38 Total Rows: 13 |
| 168 | Initial runs: 1 Merge passes: 0 IO Cost / pass: 0 |
| 169 | Total IO sort cost: 0.000000 Total CPU sort cost: 38415391 |
| 170 | Total Temp space used: 0 |
| 171 | SM join: Resc: 12.002240 Resp: 12.002240 [multiMatchCost=0.000000] |
| 172 | SM Join |
| 173 | SM cost: 12.002240 |
| 174 | resc: 12.002240 resc_io: 10.000000 resc_cpu: 76912478 |
| 175 | resp: 12.002240 resp_io: 10.000000 resp_cpu: 76912478 |
| 176 | Outer table: TAKES Alias: T |
| 177 | resc: 5.001070 card 22.000000 bytes: deg: 1 resp: 5.001070 |
| 178 | Inner table: STUDENT Alias: S |
| 179 | resc: 5.000998 card: 13.000000 bytes: deg: 1 resp: 5.000998 |
| 180 | using dmeth: 2 #groups: 1 |
| 181 | Cost per ptn: 0.015739 #ptns: 1 |
| 182 | hash_area: 124 (max=5120) buildfrag: 1 probefrag: 1 ppasses: 1 |
| 183 | Hash join: Resc: 10.017831 Resp: 10.017831 [multiMatchCost=0.000023] |
| 184 | HA Join |
| 185 | HA cost: 10.017831 |
| 186 | resc: 10.017831 resc_io: 10.000000 resc_cpu: 684944 |
| 187 | resp: 10.017831 resp_io: 10.000000 resp_cpu: 684944 |
| 188 | Join order aborted: cost > best plan cost |
| 189 | *********************** |
| 190 | (newjo-stop-1) k:0, spcnt:0, perm:2, maxperm:2000 |
| 191 | |
| 192 | ********************************* |
| 193 | Number of join permutations tried: 2 |
| 194 | ********************************* |